

Nahrávanie vlastných súborov
V Codexise je možné vlastné súbory využiť na dvoch miestach:
- na právnu analýzu dokumentu
- v chate s akýmkoľvek asistentom, kde je možné rozšíriť kontext o obsah nahraného dokumentu
Ak preferujete nahranie anonymizovaného dokumentu, odporúčame využiť bezpečnú anonymizáciu pomocou napr.: https://www.ilovepdf.com/
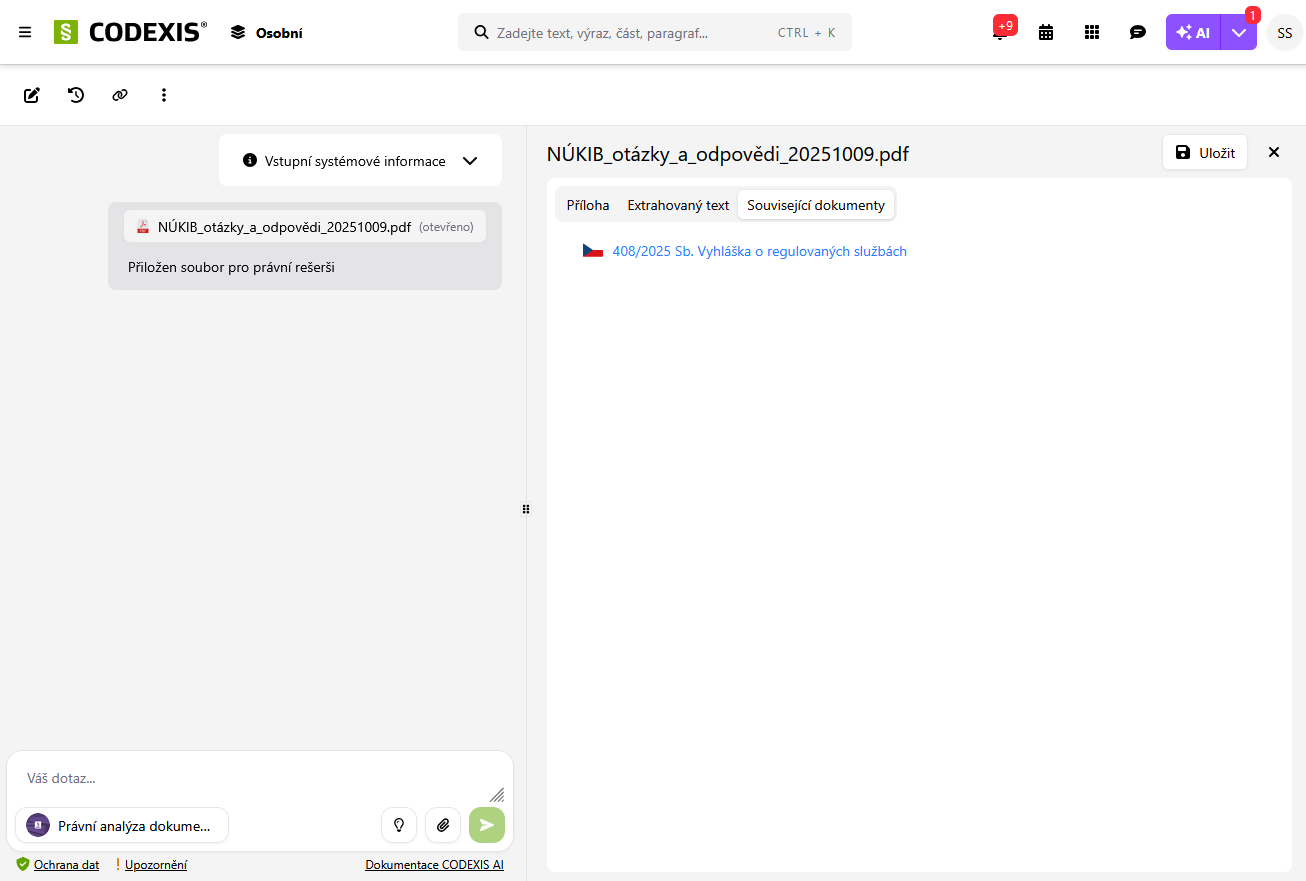
1. AI analýza vlastného súboru
AI analýza vlastného súboru v sebe kombinuje kontrolu aktuálnosti použitých právnych predpisov a možnosť analyzovať celý kontext súboru.
- analýzu spustíme z vyhľadávacieho riadka pomocou ikony upload súboru
- súbory je možné nahrať z vlastného disku

V čom je táto funkcia užitočná?
- po nahraní súboru prebehne kontrola použitých právnych predpisov a ich aktuálnosti
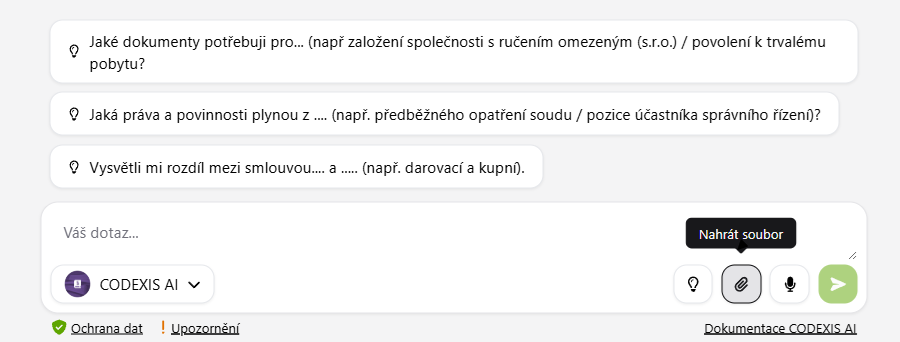
2. Rozšírenie kontextu chatu vlastným dokumentom
Nahranie vlastného dokumentu priamo do chatu umožňuje rozšíriť kontext existujúcej konverzácie. To znamená, že AI môže priamo pracovať s obsahom vášho súboru.
- dokument môžete priložiť k akémukoľvek chatu pomocou ikony prílohy (sponka)
- súbory je možné nahrať z vlastného disku alebo priamo z Mojich tém
S nahranými súbormi potom môžete napríklad
- vygenerovať zhrnutie obsahu pre rýchly prehľad
- nájsť a zvýrazniť kľúčové ustanovenia (napr. výpovedné lehoty, sankcie, rozhodcovské doložky)
- nájsť potenciálne rizikové formulácie (napr. nevyvážené záväzky)
- odhaliť chýbajúce prvky bežné v danom type zmluvy (napr. GDPR doložka v pracovnej zmluve)
- nechať si dokument preložiť do iného jazyka pri zachovaní významu
- na základe analýzy navrhnúť úpravy textu (napr. doplnenie ochrannej doložky)
- vygenerovať alternatívne znenie sporných častí
- alebo len rozšíriť obsah existujúceho chatu
- a pod.
Odporúčania pre nahrávanie súborov
- aby mohlo spracovanie textu prebehnúť rýchlo a presne, nahrávajte menšie a čitateľné dokumenty
- ideálne do 200 strán
- odporúčame Word (.docx) alebo PDF s textovou vrstvou
Prečo nie viac ako 200 strán?
Veľké súbory trvajú dlhšie a AI nemusí zvládnuť spracovať celý kontext naraz, čo môže ovplyvniť presnosť výsledkov.
Prečo nie PDF bez textovej vrstvy?
AI potrebuje textovú vrstvu, aby mohla dokument „čítať“ a spracovať obsah správne.
Ak PDF obsahuje len naskenovaný obrázok textu, systém vykoná OCR (optické rozpoznanie textu).
Tento proces môže trvať dlhšie a kvalita výsledku zodpovedá kvalite skenu – rozmazané alebo pokrivené texty sa rozpoznávajú horšie.
Ako prebieha OCR
Pri súboroch vložených do AI chatu, ktoré neobsahujú textovú vrstvu, prebieha prevod obsahu do strojovo čitateľnej textovej podoby, aby s dokumentom mohol pracovať zvolený AI model (napríklad GPT).
Tento prevod zaisťuje služba Mistral OCR. Služba Mistral OCR sa neučí na používateľských dátach, spracúvané dáta neukladá (režim Zero Data Retention) a celé spracovanie prebieha na európskych serveroch.
Ako spoznám, že PDF nemá textovú vrstvu?
Skúste v súbore označiť text myšou. Ak sa označenie nepodarí a celé PDF sa správa ako obrázok, ide o súbor bez textovej vrstvy a bude nutný OCR prevod.